서비스 디스커버리
REST API 를 이용해서 다른 서비스를 호출한다고 해봅시다. 요청을 보내기 위해서는 서비스 인스턴스가 있는 곳의 네트워크 정보를 알아야 합니다. IP 주소와 포트 정보가 되겠죠. 물리적 서버에서 돌아가는 경우라면 미리 설정 파일로 빼서 관리할 수 있으므로 큰 문제는 없습니다.
하지만 클라우드에서는 어떨까요?
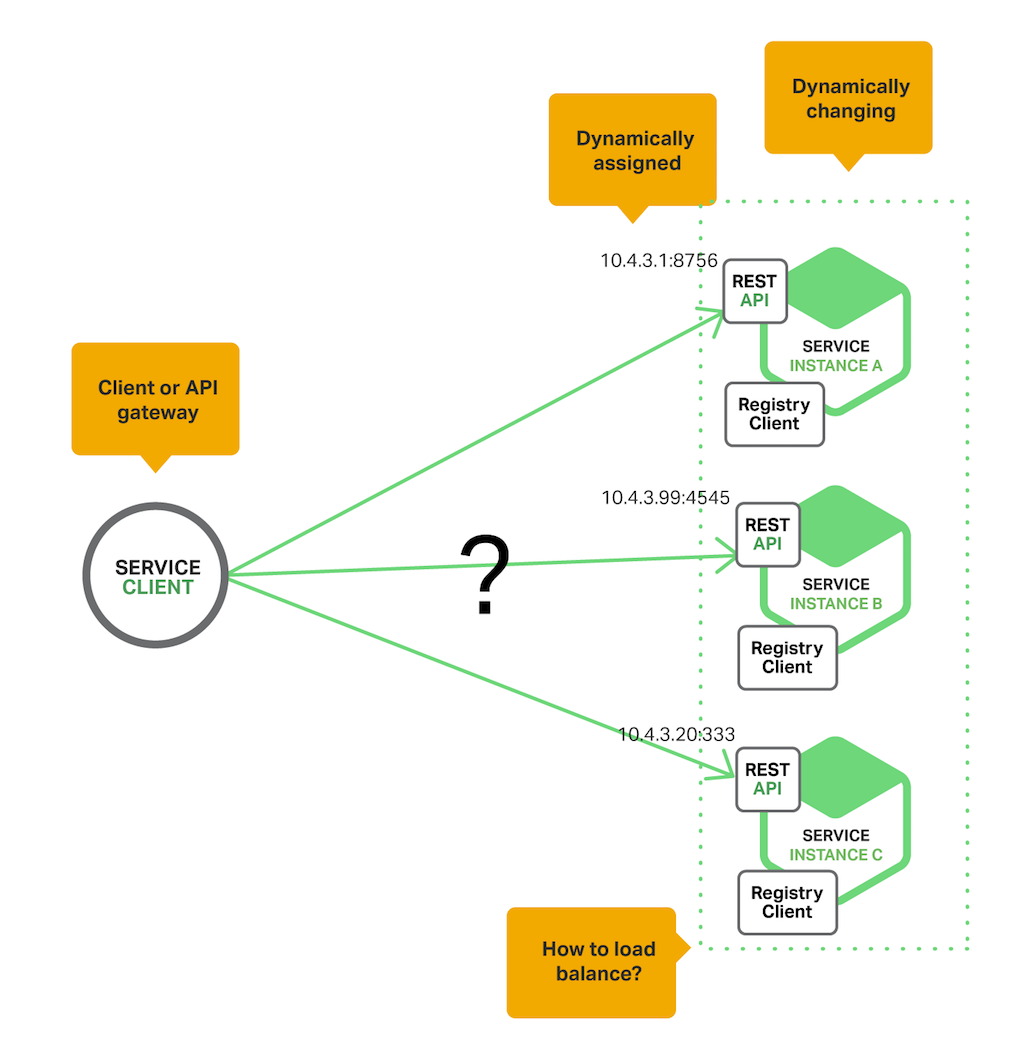
클라우드에서 인스턴스는 동적으로 할당되기 때문에 IP주소나 포트 정보가 정해지지 않은 데다가 오토스케일링도 일어나고 중지되고 복구되면서 네트워크 위치가 계속해서 바뀌게 됩니다.
따라서 클라이언트나 API 게이트웨이가 호출할 서비스를 찾는 매커니즘이 필요하고 이를 서비스 디스커버리(Service Discovery)라고 합니다. 이러한 로직을 구현하는 쪽에 따라서 두 가지 방식으로 나뉩니다.
- 클라이언트 사이드 디스커버리 패턴(Client-Side Discovery Pattern)
- 서버 사이드 디스커버리 패턴(Server-Side Discovery Pattern)
클라이언트 사이드 디스커버리
서비스 인스턴스의 네트워크 위치를 찾고 로드밸런싱하는 역할을 클라이언트가 담당하는 방식입니다.
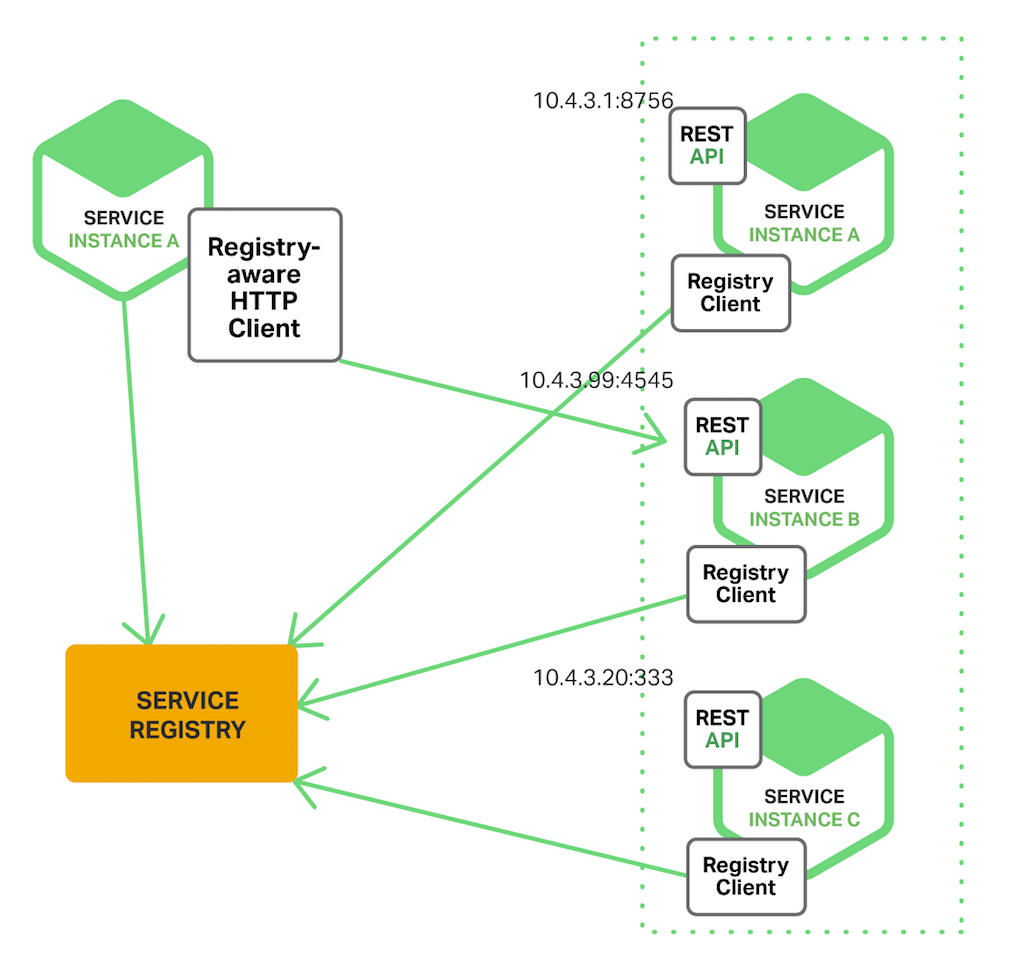
서비스 인스턴스는 시작될 때 자신의 네트워크 주소를 서비스 레지스트리(Service Registry)에 등록하고, 서비스 레지스트리는 각 서비스 인스턴스의 상태를 계속해서 체크합니다. 클라이언트는 서비스 레지스트리에 등록된 인스턴스 중 하나를 골라서 요청을 보내는 방식으로 로드밸런싱이 이루어집니다. 인스턴스가 종료되면 서비스 레지스트리에 등록된 정보는 삭제됩니다.
Netflix OSS 가 클라이언트 사이드 디스커버리 패턴의 좋은 예입니다. Netflix Eureka 는 서비스 레지스트리로 서비스 인스턴스의 등록과 가용한 인스턴스를 찾는 REST API 를 제공합니다. Netflix Ribbon 은 Eureka 와 같이 동작하는 IPC 클라이언트로 가능한 서비스 인스턴스 간 로드밸런싱을 해줍니다.
이러한 방식의 장점은 서비스 디스커버리 로직을 클라이언트가 가지고 있기 때문에 서비스에 맞는 로드밸런싱 방식을 각자 구현할 수 있다는 점입니다. 하지만 반대로 각 서비스마다 서비스 레지스트리를 구현해야 하는 종속성이 생깁니다. 만약 서비스마다 다른 언어를 사용하고 있다면 언어별 또는 프레임워크별로 구현해야겠죠.
서버 사이드 디스커버리
이번엔 반대로 서버 쪽에서 디스커버리 로직을 구현한 방식입니다.
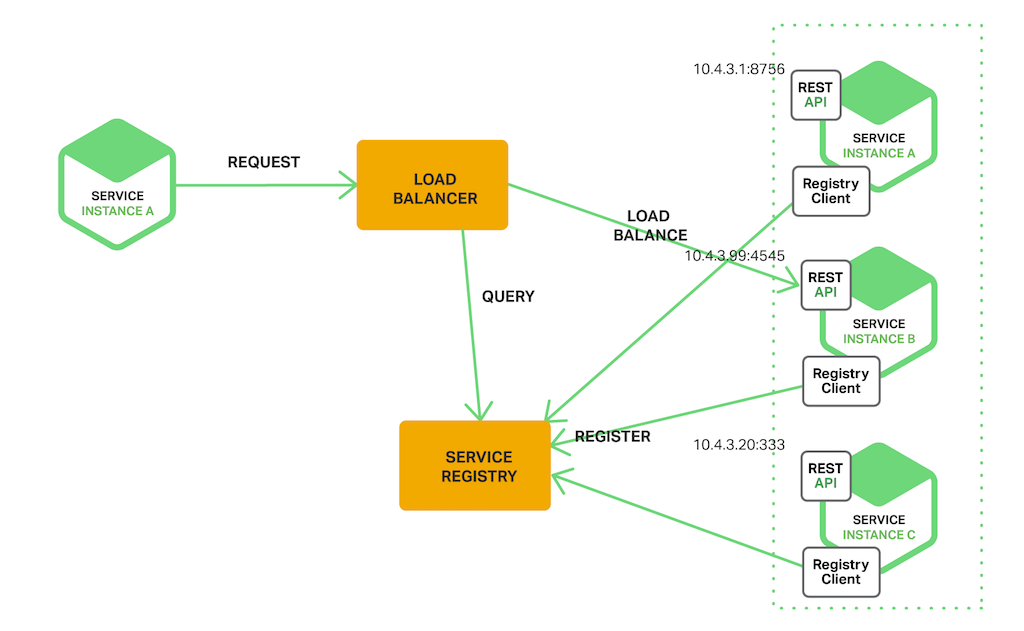
클라이언트는 로드밸런서로 요청을 보냅니다. 로드밸런서는 서비스 레지스트리를 조회해서 가용한 인스턴스를 찾고 그 중 선택해서 요청을 라우팅하는 방식입니다. 서비스 레지스트리에 등록되는 방식은 클라이언트에 있을 때와 같습니다.
AWS Elastic Load Balancer(ELB)가 서버 사이드 서비스 디스커버리 패턴의 좋은 예입니다. ELB는 일반적으로 인터넷에서 들어오는 외부 트래픽을 로드밸런싱하는 데 사용되고, VPC(Virtual Private Cloud)에서 내부 트래픽을 처리할 때 사용되기도 합니다. 클라이언트에서 DNS 이름을 이용해 ELB로 요청(HTTP 또는 TCP)을 보내면 ELB는 등록된 EC2(Elastic Compute Cloud) 인스턴스나 ECS(EC2 Container Service) 컨테이너 사이에서 부하를 분산합니다. 여기서 서비스 레지스트리 역할도 ELB가 합니다.
Kubernetes 와 Marathon 같은 환경에서는 클러스트 내 호스트 별로 프록시(proxy)를 실행합니다. 이 프록시는 서버 쪽 서비스 디스커버리의 역할을 하는데요, 클러스트 내에 가용한 서비스 인스턴스로 요청을 포워딩합니다.
서버 사이드 서비스 디스커버리 방식은 디스커버리 로직을 클라이언트에서 분리할 수 있습니다. 따라서 클라이언트 쪽에선 이런 로직을 몰라도 되고 따로 구현할 필요도 없습니다. 그리고 위에서 언급한 몇몇 배포 환경에서는 이런 로직을 무료로 제공하고 있습니다. 반면에 이 서비스 디스커버리가 죽으면 전체 시스템이 동작하지 않기 때문에 고가용성 등 더 많은 관리가 필요합니다.
서비스 레지스트리
서비스 레지스트리는 각 서비스 인스턴스의 네트워크 위치 정보를 저장하는 데이터베이스로 항상 최신 정보를 유지해야 하며 고가용성이 필요합니다.
앞서 얘기한 서비스 레지스트리인 Netflix Eureka 는 서비스 인스턴스를 등록하고 조회하는 API를 제공합니다. 각 서비스 인스턴스는 POST 요청으로 자신의 네트워크 위치를 등록하고 30초마다 PUT 요청으로 자신의 정보를 갱신해야 합니다. 등록된 서비스 정보는 DELETE 요청이나 타임 아웃으로 삭제됩니다. 그리고 등록된 서비스 정보는 GET 요청으로 조회할 수 있습니다.
Netflix 는 Eureka 서비스를 여러 개의 Amazon EC2 위에 실행하고 가용 영역(Availability Zones)에 배포합니다. 이렇게 여러 인스턴스가 각자 격리된 위치에서 실행되도록 구성하면 고가용성을 유지할 수 있습니다. 각 Eureka 서버가 실행되는 EC2 인스턴스는 Elastic IP 주소를 가지고 있고 DNS 의 TEXT 레코드는 클러스터 정보를 저장합니다. Eureka 서버가 시작되면 DNS 에 Eureka 클러스터 설정 정보를 조회하고 사용하지 않는 주소에 스스로 Elastic IP 를 할당합니다.
따라서 Eureka 클라이언트는 DNS 를 이용해 Eureka 서버의 네트워크 위치를 조회할 수 있습니다. 같은 가용 영역에 있는 Eureka 서버에 먼저 접속하겠지만 가능한 인스턴스가 없으면 다른 가용 영역의 인스턴스에 접속하게 됩니다.
서비스 레지스트리를 사용하는 다른 예는 다음과 같습니다.
서비스 등록
마지막으로 서비스 등록 패턴에 대해 살펴보겠습니다. 각 서비스는 서비스 레지스트리에 각자의 정보를 등록하고 해제해야 한다고 설명드렸는데요, 여기에는 두 가지 방식이 있습니다.
- 셀프 등록 패턴 (Self Registration Pattern) : 서비스 스스로 등록을 관리.
- 써드 파티 등록 패턴 (3rd Party Registration Pattern) : 제3의 시스템에서 등록을 관리.
셀프 등록 패턴
등록과 관리를 하는 주체가 서비스인 방식입니다. 각 서비스는 서비스 레지스트리에 자신의 정보를 등록하고, 필요하다면 주기적으로 자신이 살아있다는 신호(heartbeat)를 계속 전송합니다. 만약 이 정보가 일정 시간이 지나도 오지 않는다면 서비스에 문제가 발생한 것으로 보고 등록이 해제될 겁니다. 그리고 서비스가 종료될 때는 등록을 해제합니다.
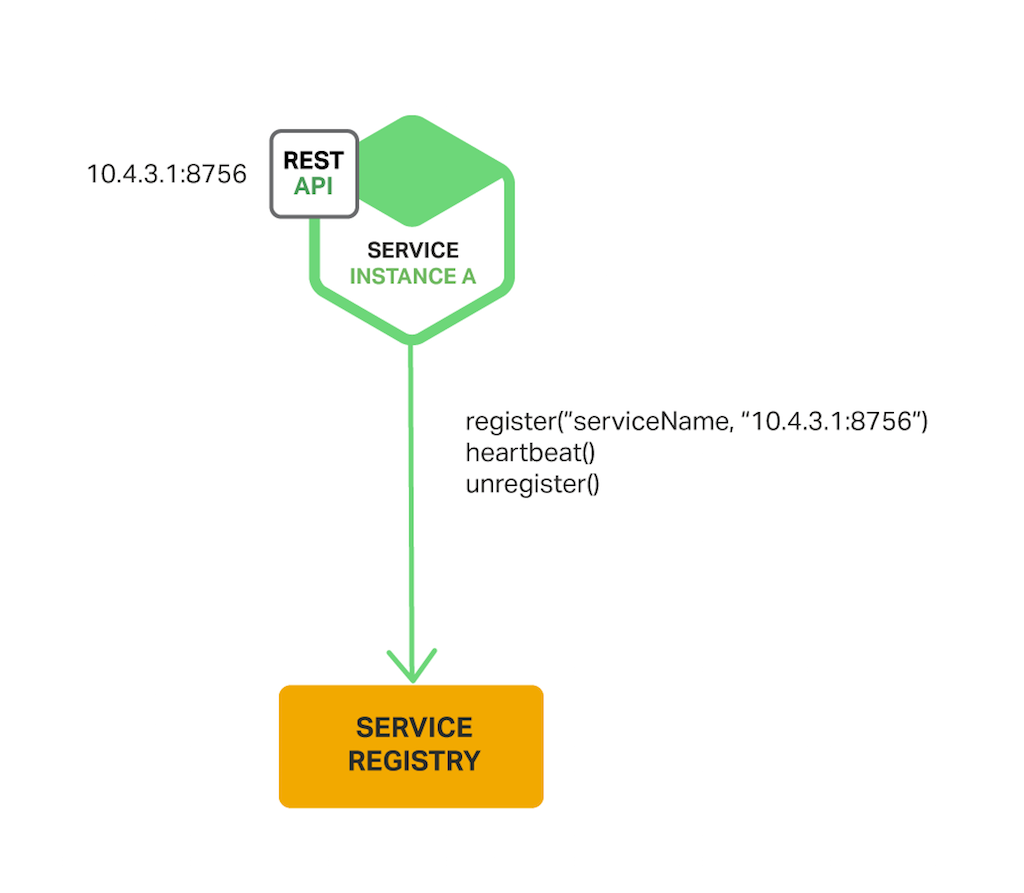
앞서 살펴본 Eureka 클라이언트가 이에 해당합니다. Spring Cloud project 에서는 @EnableEurekaClinet 어노테이션을 이용해 쉽게 구현할 수 있습니다.
이 방식은 다른 컴포넌트 없이 간단하게 구성할 수 있다는 장점이 있지만 각 서비스에서 서비스 등록 로직을 구현해야 한다는 단점이 있습니다.
써드 파티 등록 패턴
대신 외부에서 서비스 등록을 관리하는 방법이 있습니다. 서비스 등록을 관리하는 서비스 레지스트라(Service Registrar)를 따로 두는 것이죠. 서비스 레지스트라는 각 서비스 인스턴스의 변화를 폴링(polling) 이나 이벤트 구독으로 감지해서 서비스 레지스트리에 계속 업데이트합니다.
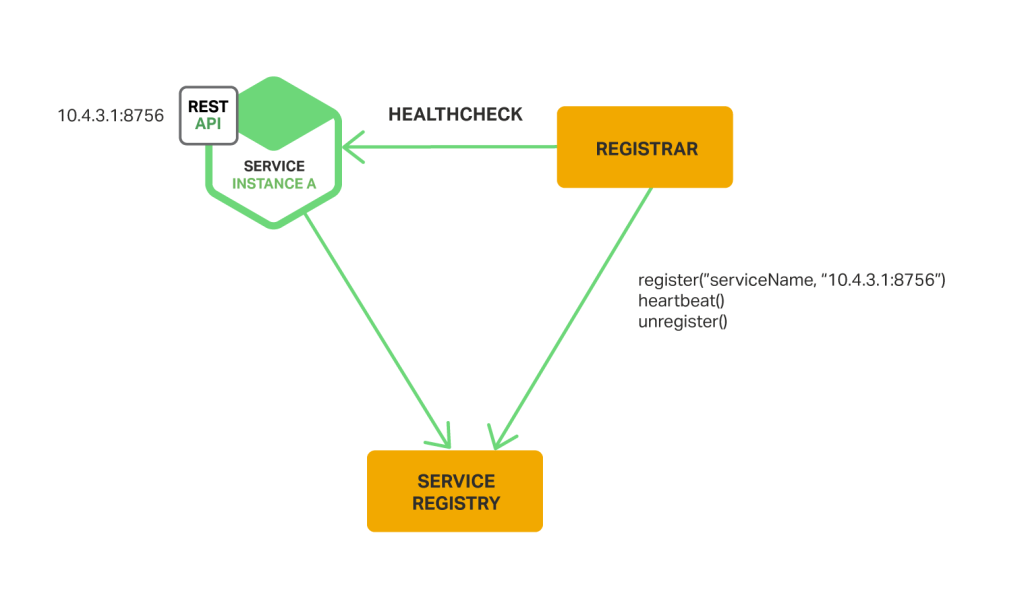
이런 방식의 예로는 Registrator가 있습니다. Docker 컨테이너로 배포된 서비스 인스턴스의 등록을 관리하는 오픈소스 프로젝트입니다. etcd 와 Consul 를 포함해 여러 서비스 레지스트리를 지원합니다.
다른 예로는 NetflixOSS Prana 가 있습니다. 기본적으로 non-JVM 언어로 작성된 서비스를 위해서 만들어진 애플리케이션으로 애플리케이션과 함께 실행되는 방식입니다(sidecar application). Eureka 서비스 인스턴스를 등록 및 해제하는 역할을 합니다. 이 외에도 배포 환경에 내장된 서비스 레지스트라를 사용할 수도 있습니다.
이런 방식의 장점은 서비스에서 서비스 등록 및 관리 로직을 분리할 수 있다는 점, 중앙에서 통제가 가능하다는 점이고 반대로 서비스 레지스트라가 멈추면 안되기 때문에 고가용성 등 더 많은 관리가 필요한 단점도 있습니다.