분산 데이터 관리의 어려움
보통 모놀리식(monolithic) 애플리케이션에서는 하나의 관계형 DB(Relational database)를 사용합니다. DB 작업은 트랜잭션(transaction)이라는 단위로 수행이 되는데 RDB의 장점은 트랜잭션이 ACID하도록 만들어줍니다.
- 원자성(Atomicity): 작업이 완전히 성공하든지 또는 완전히 실패하도록 만들어서 애매한 상태가 없는 것을 보장.
- 일관성(Consistency): 데이터를 일관된 상태로 유지하는 것을 보장.
- 격리성(Isolation): 다른 작업과 꼬이지 않도록 트랜잭션이 동시에 실행되지 않는 것을 보장.
- 지속성(Durable): 데이터를 안전하게 보관하기 위해 트랜잭션을 커밋(commit)하면 되돌릴 수 없는 것을 보장.
SQL을 사용할 수 있는 것도 RDB의 장점입니다. 여러 테이블에서 데이터를 쉽게 가져올 수 있고 최적화된 방법으로 데이터를 조회할 수 있습니다.
폴리글랏 퍼시스턴스
마이크로서비스 아키텍처에선 어떨까요? 각 마이크로서비스는 각자의 DB를 가지고 있고 다른 서비스의 DB 에 접근할 수 없습니다. 제공된 API 를 통해서만 접근이 가능합니다. 따라서 데이터를 캡슐화하고 결합도를 낮출 수 있습니다.
또한 이런 구조는 각자의 서비스의 기능과 역할에 맞는 DB 를 선택할 수 있는 장점도 있습니다. RDB 뿐만 아니라 NoSQL 을 섞어서 사용할 수 있고, 분산형 검색 엔진인 Elasticserach 나 그래프 데이터베이스인 Neo4j 를 사용할 수도 있습니다. 이렇게 각 서비스의 기능에 따라 적합한 데이터베이스를 선택해서 사용하는 방식을 폴리글랏 퍼시스턴스(Polyglot Persistence)라고 합니다.
하지만 데이터가 분산되어 있기 때문에 관리하기가 어렵습니다. 같은 데이터를 여러 서비스에서 사용한다면 데이터 중복도 발생하고 업데이트 시 여러 서비스의 DB 에 함께 반영해야 하므로 일관성을 유지하기 어렵습니다. 각자 사용하는 DBMS 가 다른 것도 문제가 되겠죠.
일관된 데이터
먼저 어떻게 일관된 데이터를 유지할 수 있을까요? B2B 스토어를 예로 들어보겠습니다. 고객(Customer) 서비스는 신용 정보를 포함한 고객 정보를 관리하고, 주문(Order) 서비스는 주문 정보를 관리합니다. 그런데 주문 시 해당 고객의 신용 한도(CREDIT_LIMIT)가 넘지 않아야 하기 때문에 고객의 신용 한도 정보가 필요합니다.
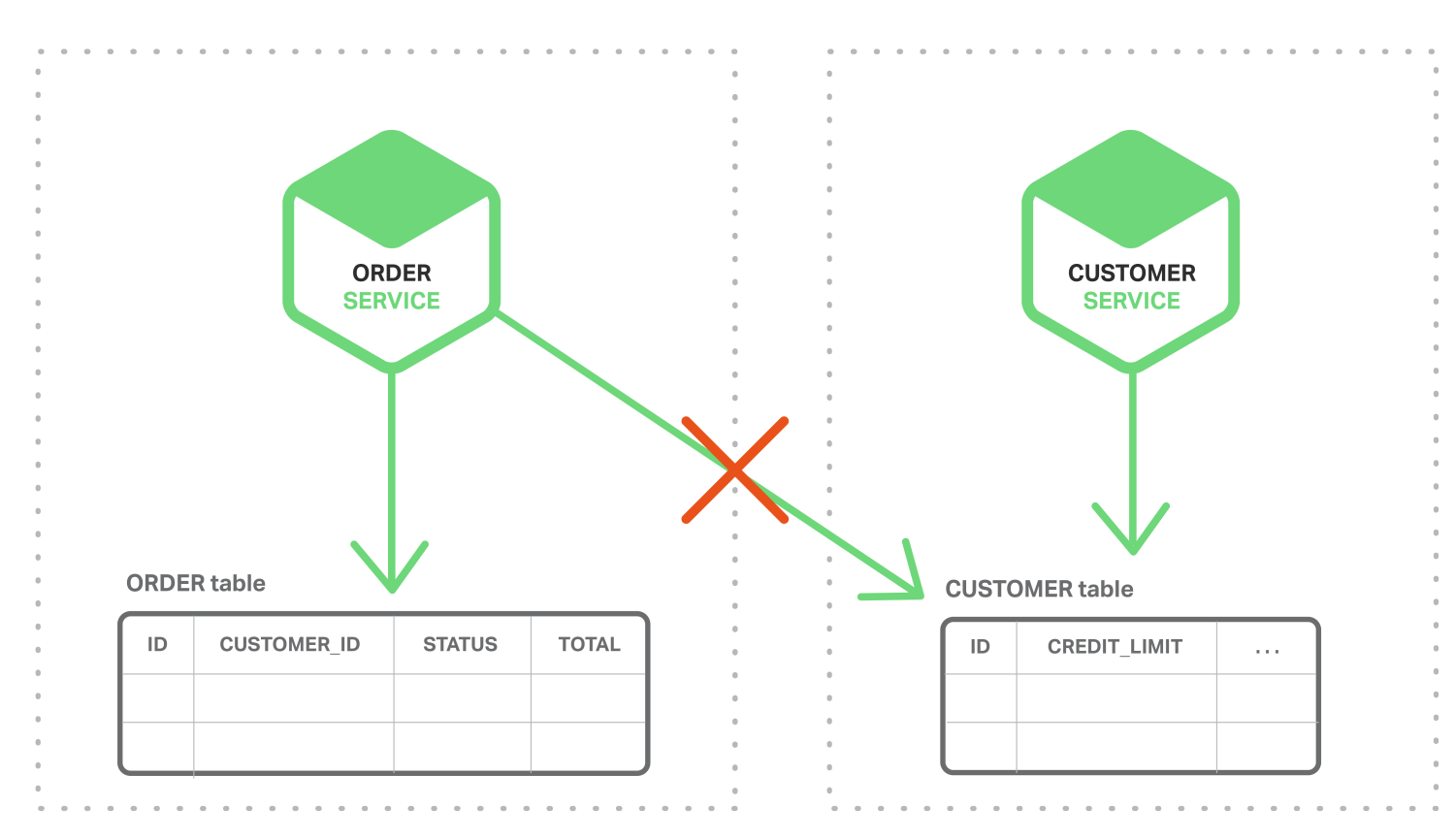
하지만 주문 서비스는 고객 테이블(CUSTOMER)에 바로 접근할 수가 없습니다. 그리고 주문을 하는 경우 고객의 신용 정보까지수정을 해야 하는데 이런 경우에 2단계 커밋(two-phase commit protocol)이라는 분산 트랜잭션을 사용할 수 있습니다.
분산 컴퓨팅 환경의 이론 중 하나인 CAP 정리 에 따르면 다음과 같은 세 가지 조건을 모두 만족하는 분산 컴퓨터 시스템은 없다고 합니다.
- 일관성(Consistency): 모든 노드가 같은 순간에 같은 데이터를 볼 수 있음.
- 가용성(Availability): 모든 요청이 성공 또는 실패 결과를 반환할 수 있음.
- 분할내성(Partition tolerance): 메시지 전달이 실패하거나 시스템 일부가 망가져도 시스템이 계속 동작할 수 있음.
따라서 이 조건들 중에 선택을 해야하는데, 대부분의 경우 일관된 데이터를 위해서 가용성이나 분할내성을 포기할 수는 없습니다. 시스템이 멈추지 않고 동작하게 하는 것이 더 중요하다고 보기 때문입니다. 게다가 대부분의 NoSQL DB는 2단계 커밋을 지원하지 않습니다.
분산된 데이터 조회
두 번째 문제는 여러 서비스에서 데이터를 조회하는 일입니다. 위의 예에서 고객 정보와 함께 고객의 최근 주문 내역을 보여줘야 한다고 해봅시다. RDB 모놀리식이라면 각 테이블을 JOIN 해서 구할 수 있겠지만 마이크로서비스에서는 각 서비스에서 가져온 데이터를 가져와 직접 데이터를 조인해야 합니다. 게다가 NoSQL 은 PK(Primary Key) 기반의 조회밖에 할 수 없어서 더 어려워질 수 있습니다.
이벤트 주도 아키텍처
이런 문제점들을 해결하기 위해 이벤트 주도 아키텍처(event‑driven architecture)를 적용할 수 있습니다. 이벤트 형태로 여러 서비스에게 메시지를 동시에 전달할 수 있기 때문에 일관되게 데이터를 수정할 수 있습니다. 해당 데이터를 수정해야 하는 이벤트가 발생하면 연관된 서비스들이 이벤트를 구독하고 있다가 메시지를 받아서 데이터를 갱신하는 것이죠. 위에서 살펴본 예제에 이벤트 주도 아키텍처를 적용해보겠습니다.
일관성
먼저 주문서비스에서 주문을 만들고 Order Created 이벤트를 발행합니다.
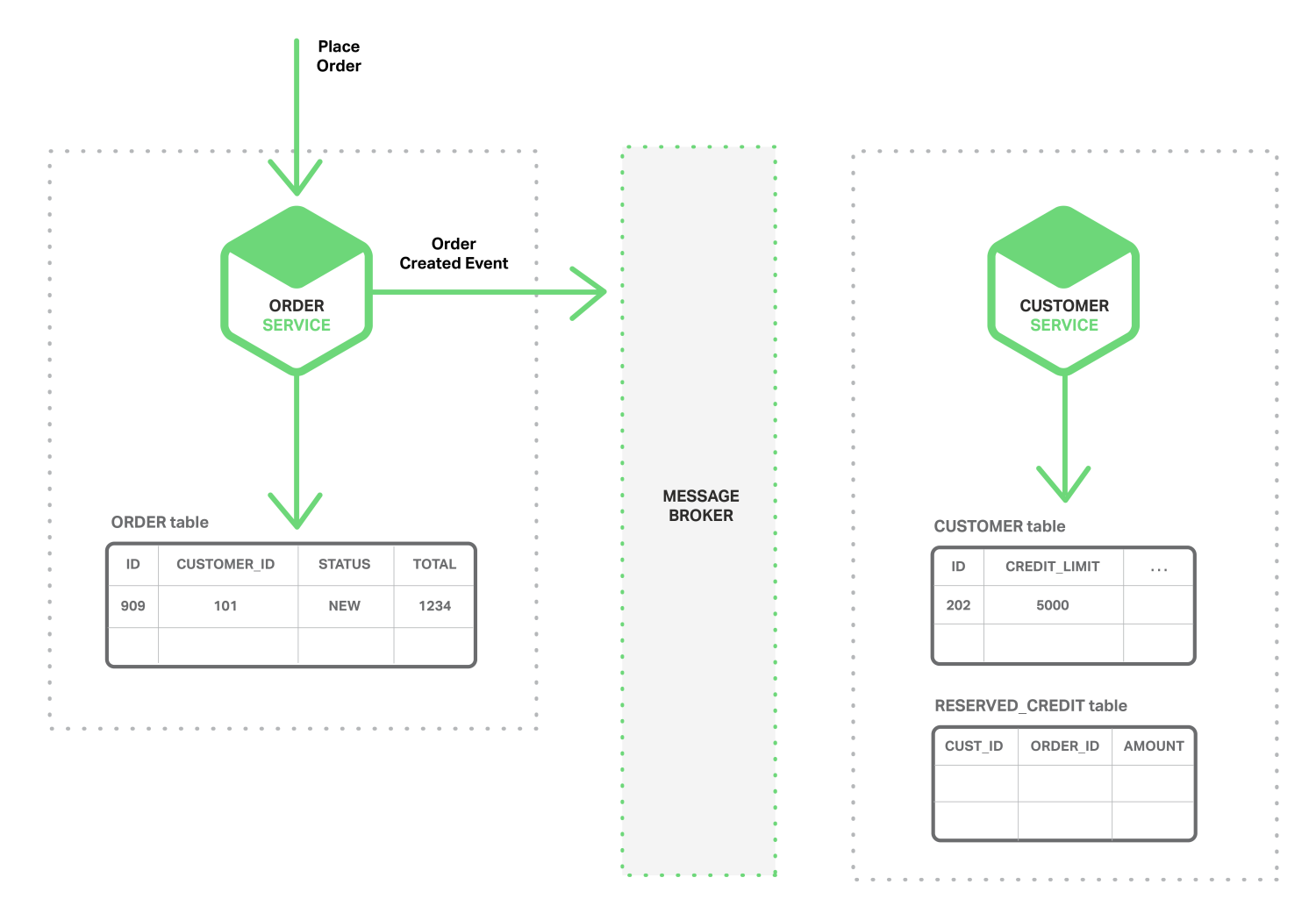
해당 이벤트를 구독하고 있던 고객 서비스가 예약한 신용 정보를 추가하고 Credit Reserved 이벤트를 발행합니다.
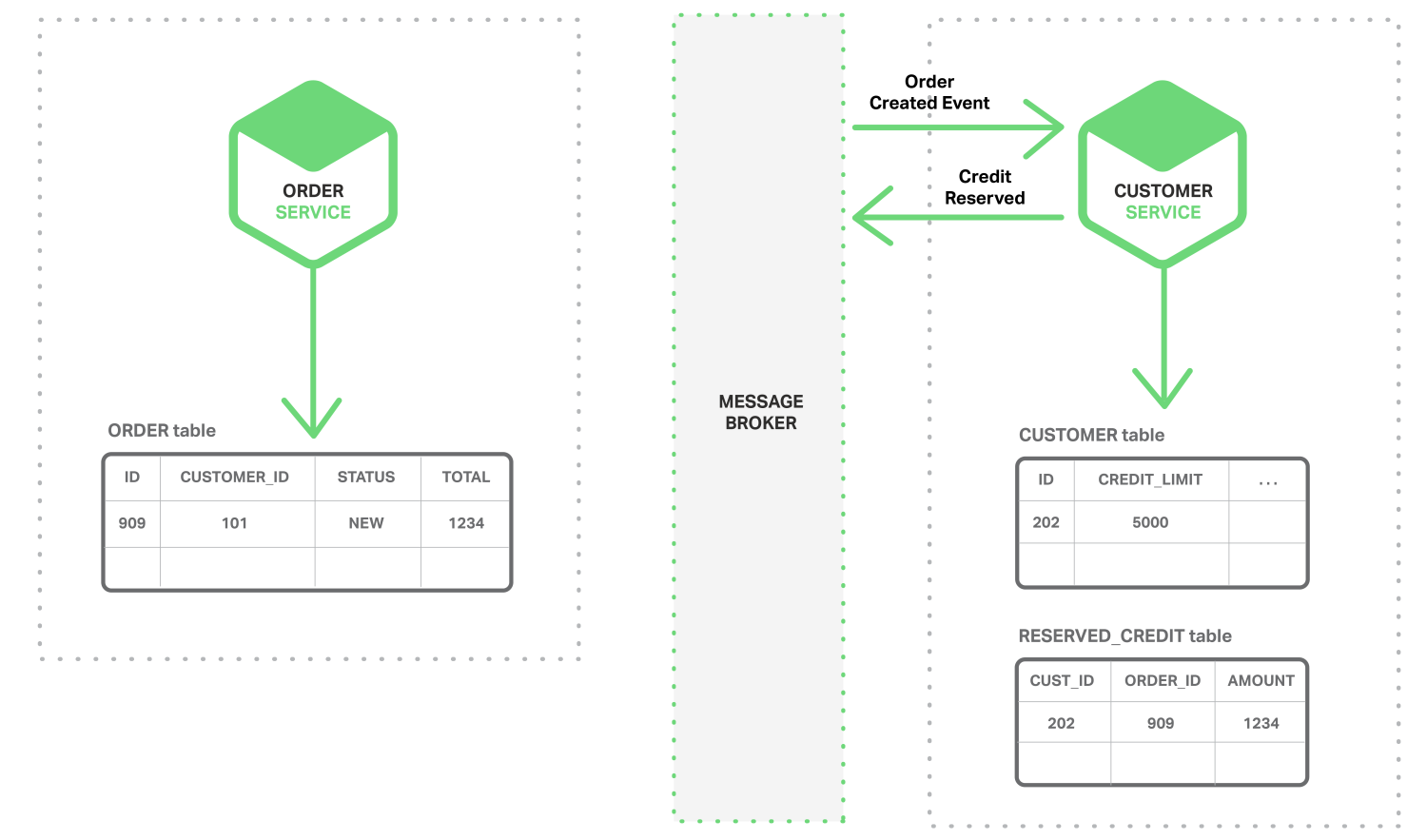
해당 이벤트를 구독하고 있는 주문 서비스가 주문의 상태를 OPEN 으로 변경합니다.
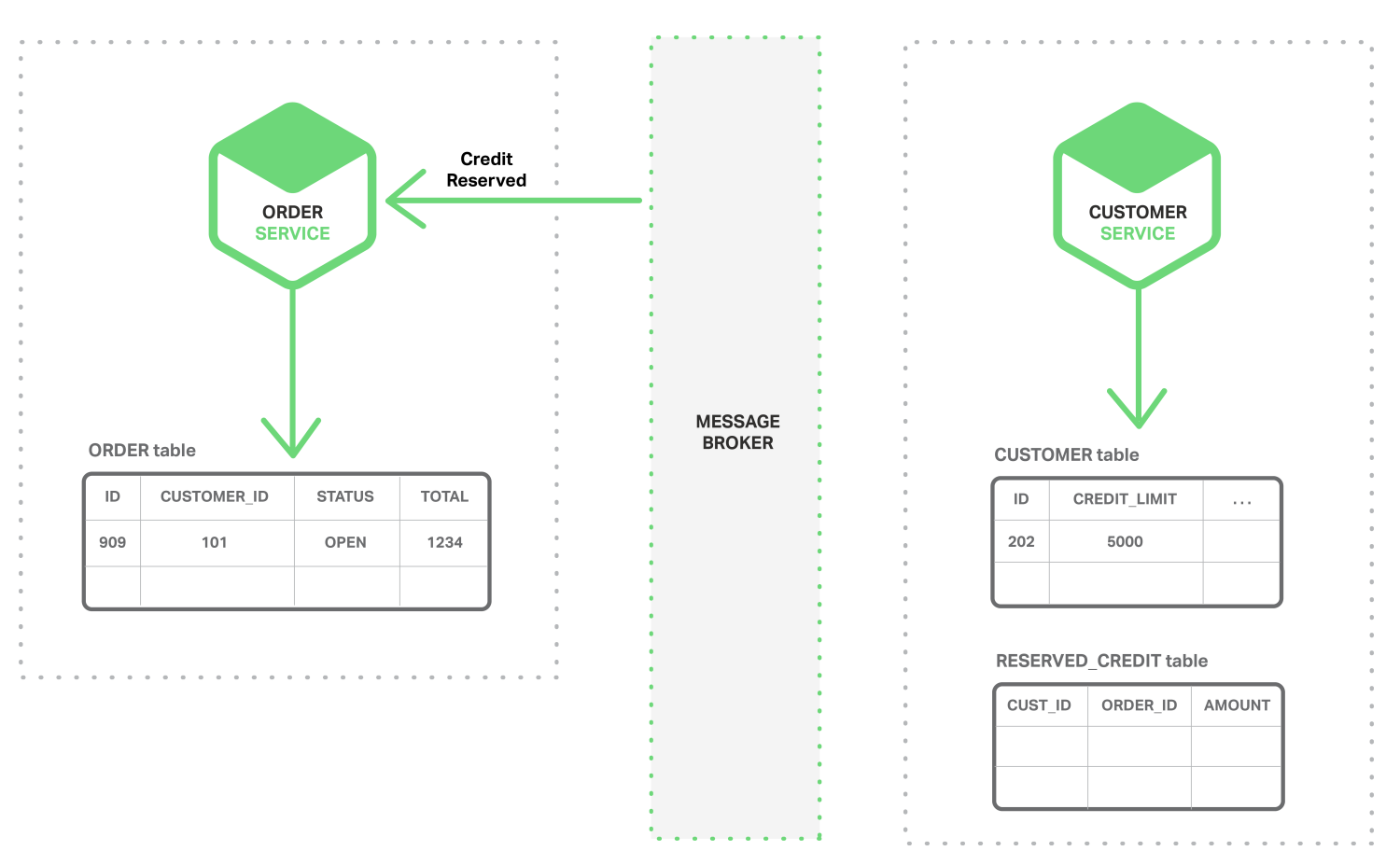
이런 구조라면 여러 서비스에서 동시에 데이터를 수정하면서 일관성을 유지될 수 있습니다. 물론 각 서비스의 DB 가 원자성을 보장하고 메시지 브로커가 각 이벤트를 최소한 한번 전달하는 것이 보장되어야 합니다. 하지만 ACID 트랜잭션만큼은 아닙니다.
분산된 데이터 조회
다음은 데이터를 조인하는 문제를 해결해봅시다. 앞서 살펴본 고객 주문 내역을 볼까요? 두 서비스를 하나로 합쳐서 생각할 수 없으니 새로운 서비스를 하나 만듭니다. 따로 고객의 주문 내역을 저장하는 서비스(고객 주문 내역 뷰 서비스)를 하나 만드는 겁니다. 이 서비스는 고객 주문 내역 자체를 수정하지는 않고 조회 시 보여주는 역할만 합니다. 따라서 필요한 이벤트(고객, 주문)를 모두 구독하고 해당 데이터가 수정이 될 때마다 자신의 데이터를 갱신합니다.
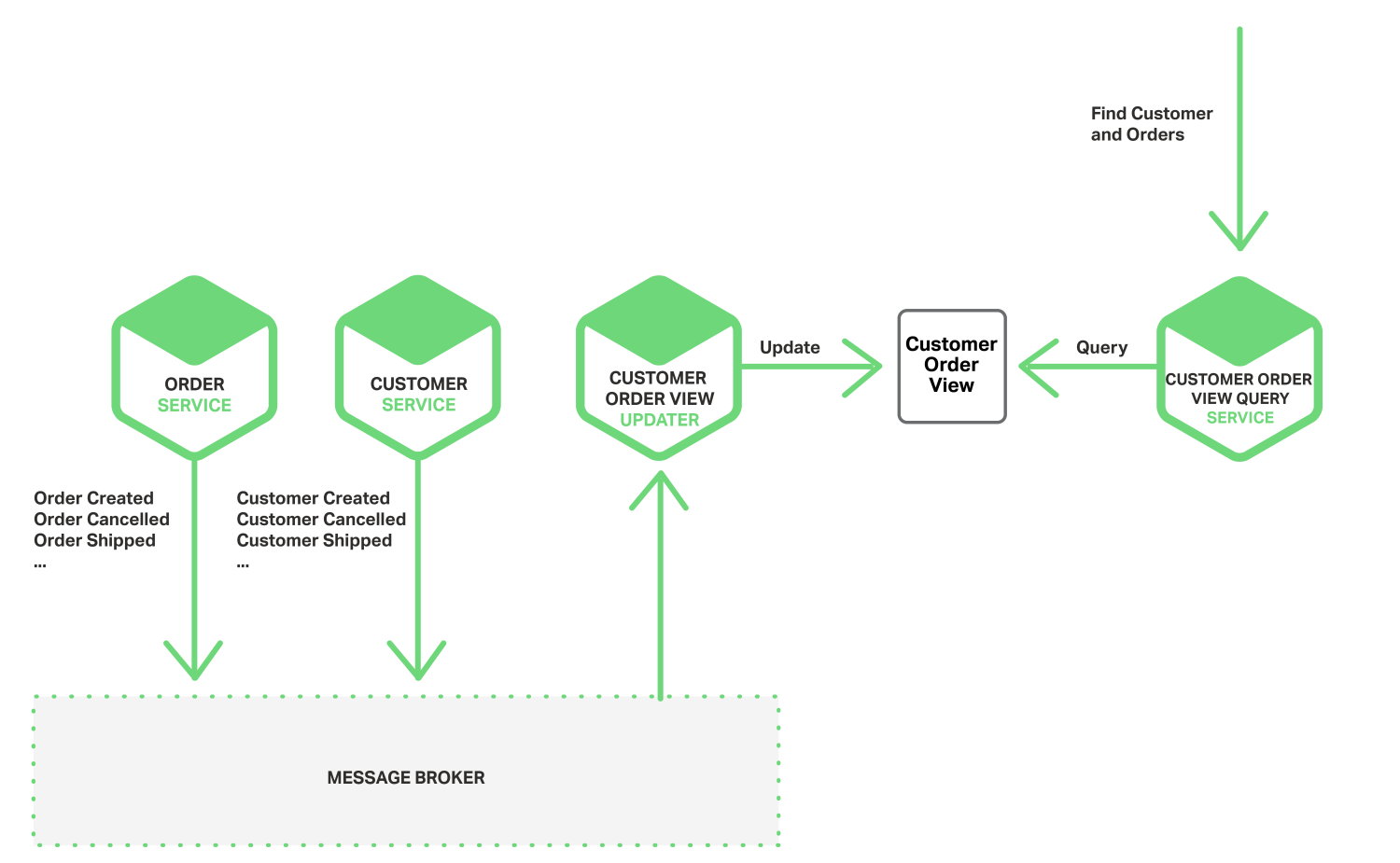
그림에서는 고객 주문 내역 조회 서비스를 따로 만들었지만 고객 내역 뷰 서비스에서 조회 API 를 제공하는게 나아보이네요.
이처럼 이벤트 주도 아키텍처를 이용해서 문제를 해결할 수 있었는데요, 단점도 있습니다.
- ACID 트랜잭션에 비해 구조가 복잡합니다.
- 오류가 발생하면 애플리케이션 레벨에서 반영한 내용을 취소하는 트랜잭션을 구현해야 합니다.
- 뷰를 사용하는 경우 반영되기 전에 데이터가 불일치할 수 있습니다.
- 이벤트가 여러 번 발생하는 경우를 탐지해서 중복된 이벤트는 무시해야 합니다.
원자성
위에서 살펴본 단점 중 하나가 원자성입니다. 데이터를 수정하고 이벤트를 발행했을 때 이벤트를 받은 쪽에서도 데이터를 수정해줘야 원자성이 보장됩니다. 하지만 데이터를 수정은 했는데 이벤트를 생성하기 전에 에러가 나서 이벤트를 생성하지 못하면 성공도 아니고 실패도 아닌 어정쩡한 상태가 됩니다. 원자성을 잃어버리게 되죠. 어떻게 하면 해결할 수 있을까요?
로컬 트랜잭션을 이용해 이벤트 발행하기
첫 번째 방법은 로컬 트랜잭션을 이용해서 이벤트를 발행하는 방법입니다. 로컬 트랜잭션은 원자성이 보장되기 때문에 이를 이용해서 이벤트를 확실하게 발생시키는 방법입니다. 구현하는 방법은 이벤트 테이블(EVENT)를 따로 만들어서 로컬 트랜잭션을 이용해서 이벤트 테이블에 데이터를 넣고 이벤트 퍼블리셔가 이벤트 테이블을 확인해서 메시지 브로커에 이벤트를 발행합니다.
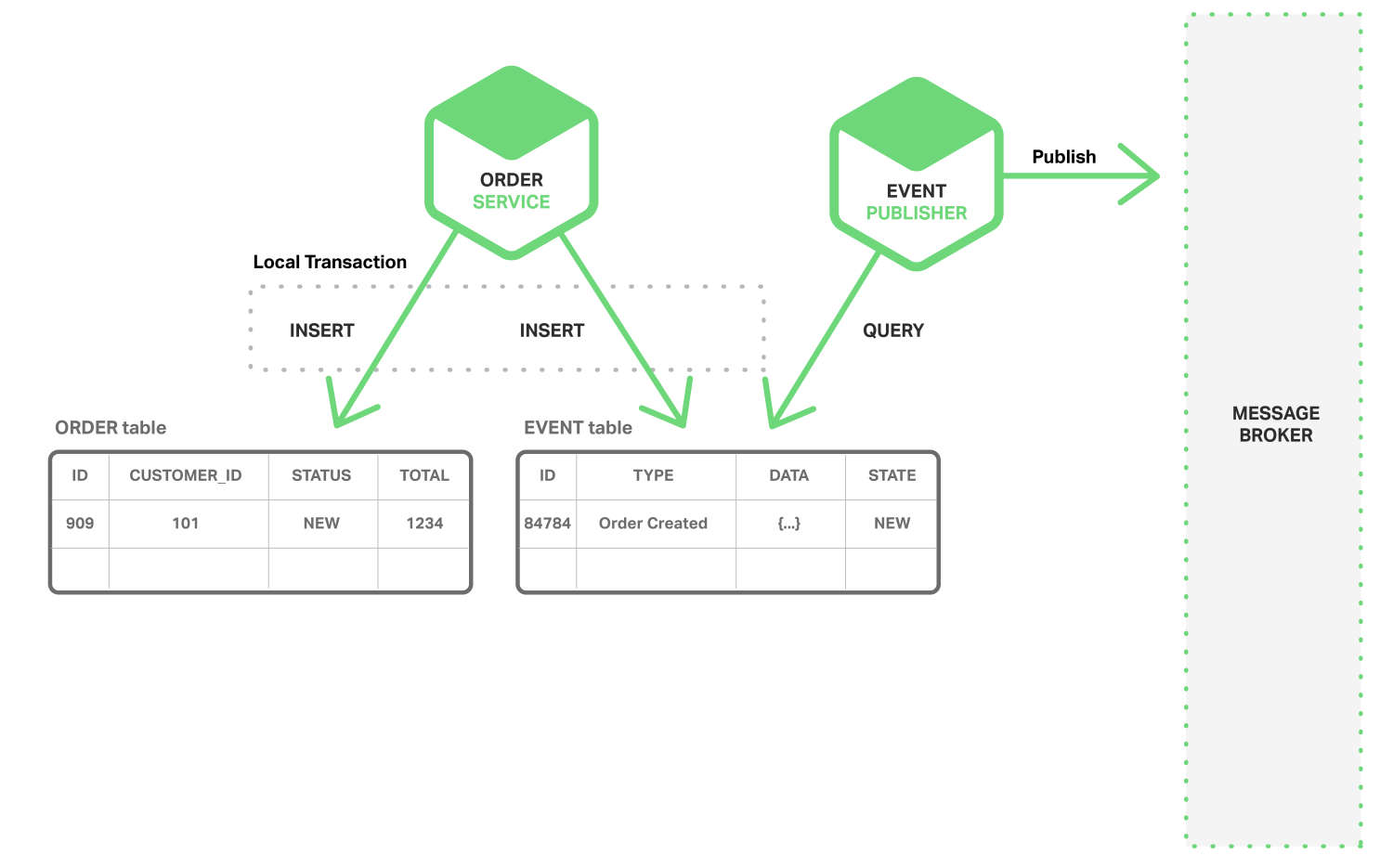
하지만 개발자가 두 테이블에 데이터를 insert 해야 하는데 실수로 빼먹을 가능성이 있습니다. 그리고 RDB 가 아닌 NoSQL 에서는 ACID 트랜잭션이 아니기 때문에 한계가 있습니다.
DB 트랜잭션 로그를 모아서 이벤트 발행하기
두 번째 방법은 DB 의 트랜잭션 로그를 모아서 이벤트를 발행하는 방법입니다. 트랜잭션 로그를 모아서 분석한 후 이벤트를 발행하면 이벤트 발행을 보장할 수 있고 비즈니스 로직과 이벤트 발행 기능을 분리할 수 있습니다.
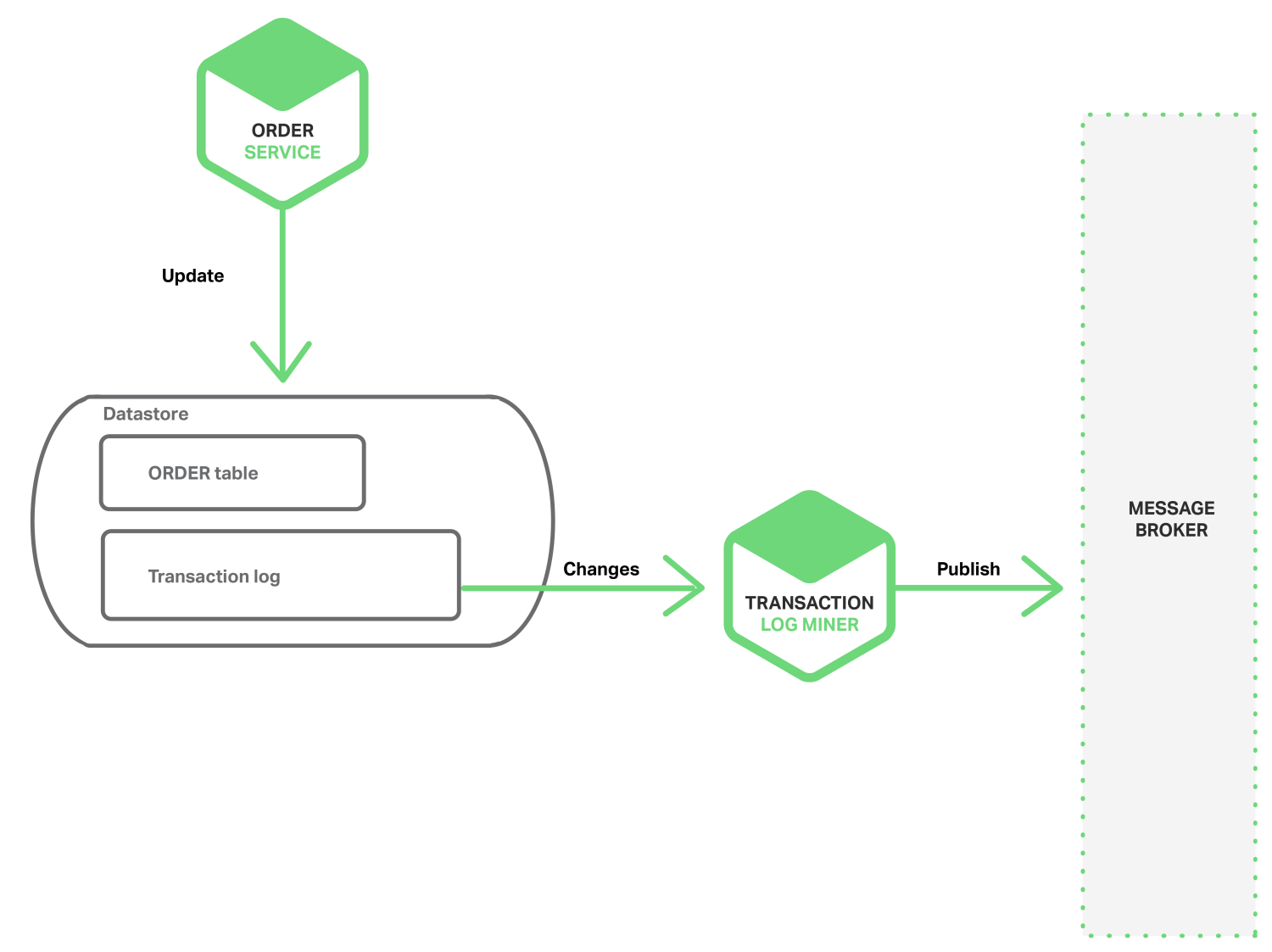
이를 구현한 예로는 오픈소스인 LinkedIn Databus 가 있습니다. Databus 는 오라클(Oracle) 트랜잭션 로그를 모아서 수정이 있는 경우 이벤트를 발행합니다. NoSQL 쪽에서는 AWS DynamoDB 의 스트림 매커니즘 이 있습니다. 이 스트림에는 지난 24시간 동안 DynamoDB 테이블 항목의 변경 정보(create, update, delete)가 기록되며 각 스트림 기록은 한 번만 나타나고 실제 항목 수정과 동일한 순서로 나타납니다. 애플리케이션은 이 정보를 읽어서 이벤트를 발행하는 등 처리를 할 수 있습니다.
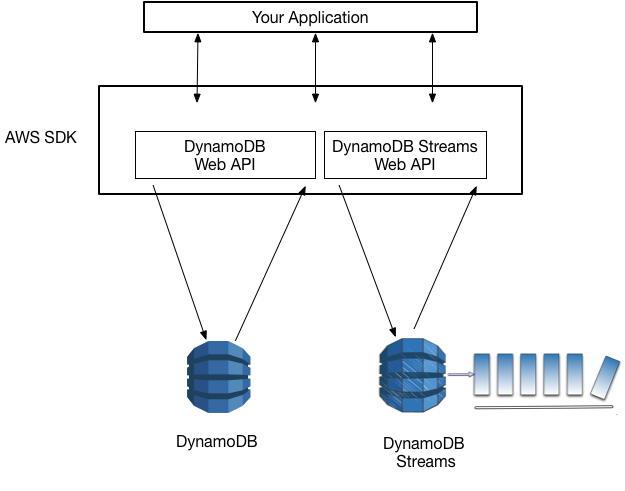
하지만 각 DB마다 로그 포맷이 다르기 때문에 적용하기 쉽지 않을 수 있고, low-level 인 로그에서 high-level 인 비즈니스 이벤트를 만들어야 한다는 점이 어렵습니다.
이벤트 소싱 사용하기
이벤트 소싱(Event Sourcing)은 근본적으로 저장하는 개념이 다릅니다. 비즈니스 개체의 현재 상태를 저장하는대신 상태를 변경하는 이벤트 내역을 목록으로 저장합니다. 그리고 이 이벤트 내역을 순서대로 재생하면서 개체의 현재 상태를 재구성합니다. 이벤트 하나를 저장하는 것은 원자성이 유지되기 때문에 이벤트 소싱을 이용해 원자성을 유지할 수 있습니다.
앞서 살펴본 예제에 적용해보겠습니다. 주문 서비스가 주문 테이블에 데이터를 저장했던 것과 달리 이벤트 소싱을 이용해서 상태를 변경하는 이벤트(Created, Approved, Shipped, Cancelled)를 저장합니다. 각 이벤트는 나중에 주문 상태를 재구성하기에 충분한 데이터를 가지고 있습니다. 이벤트 정보는 추가만 가능하고 수정이나 삭제는 할 수 없습니다.
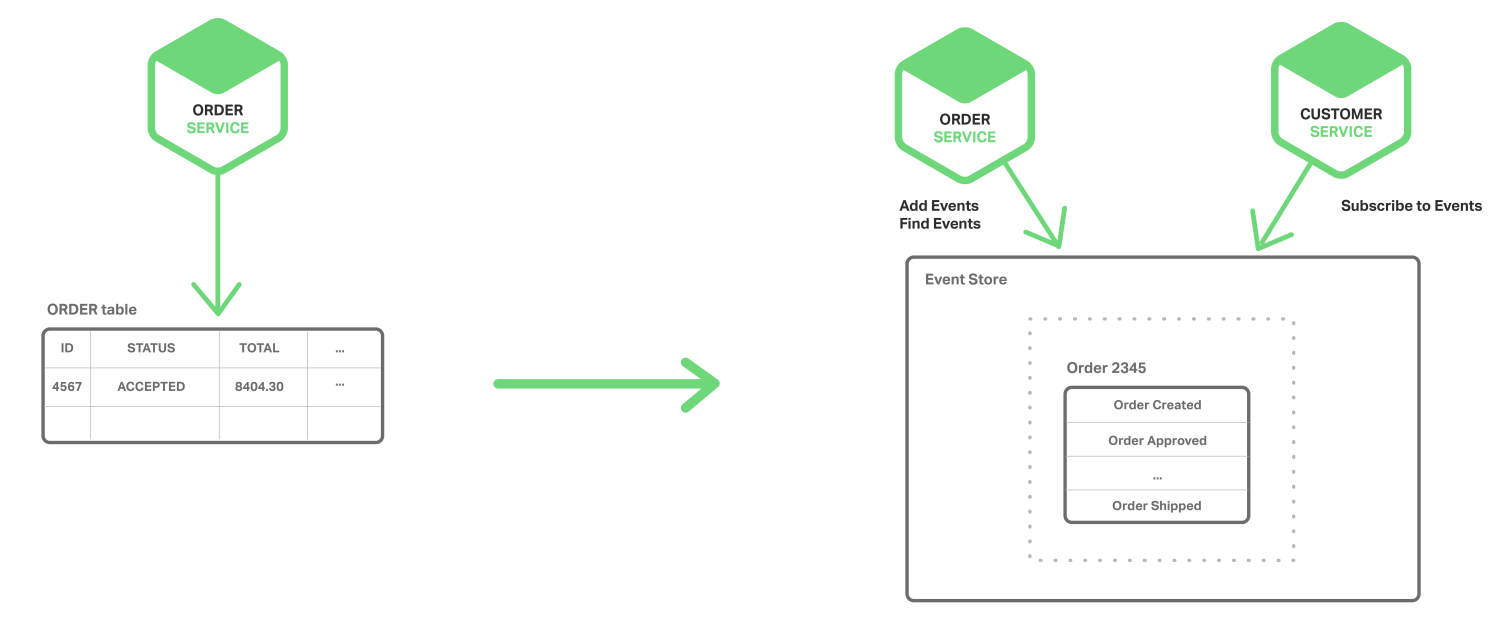
이벤트 스토어(Event Store)는 이벤트를 저장하는 DB 를 가지고 있고 이벤트를 저장 및 조회하기 위한 API 를 제공합니다. 그리고 이벤트 스토어는 이벤트를 전달하는 메시지 브로커의 역할도 합니다.
이 이벤트 스토어가 이벤트 주도 마이크로서비스의 핵심입니다. 상태를 저장하지 않고 이벤트를 저장함으로써 이벤트가 유실되지 않고 이벤트 스토어에서 이벤트를 관리하기 떄문에 여러 서비스에서 다른 값이 파편화되어 저장되는 것도 피할 수 있습니다. 게다가 따로 이력을 관리하는 테이블 없이도 특정 시점의 상태를 조회할 수 있습니다.
하지만 특정 시점의 데이터를 조회하기 위해서 전체 이벤트 내역을 게속해서 반복해야 한다면 비합리적이죠. 그래서 명령(데이터를 변경하는 create, delete, update)과 쿼리(데이터를 조회하는 read)의 책임을 분리하는 모델인 CQRS(Command Query Responsibility Segregation, 명령 및 쿼리 책임 분리)를 사용해야 합니다. 간단하게 이벤트를 저장만하는 명령 모델과 복잡하게 데이터를 재구성해야 하는 쿼리 모델을 분리하고 쿼리 모델에서는 특정 시점 데이터를 스냅샷으로 기록해 데이터 재구성 작업이 줄어듭니다.
참고
- Event-Driven Data Management for Microservices | NGINX Blog
- CQRS(명령 및 쿼리 책임 분리) 패턴 | Microsoft Azure
